Pengenalan PyTorch untuk Deep Learning


Tulisan ini adalah catatan belajar PyTorch Udacity Scholar nd188. Semua gambar milik kelas tersebut. Kelas ini sekarang tersedia FREE sebagai ud188.
Instalasi paket torch dan torchvision, sesuaikan dengan paket manager yang digunakan 1, misalnya pip atau conda.
Misalnya menggunakan pip, di linux ini akan mendownload paket torch sekitar 750MB:
pip install torch torchvision
Untuk mengecek apakah paketnya sudah terinstal dengan baik.
from __future__ import print_function
import torch
x = torch.rand(5, 3)
print(x)
Untuk yang menggunakan GPU CUDA, bisa mengecek dengan cara berikut.
import torch
torch.cuda.is_available()
Kita akan menggunakan kode yang sudah tersedia di github repo udacity 2, di dalamnya ada direktori intro-to-pytorch.
Untuk menggunakan jupyter notebook (iPython Notebook), kita butuh install paket jupyter dan notebook. Atau bisa juga menggunakan google colab, tapi butuh memindahkan file atau copy-paste ke google colab.
pip install jupyter notebook
Dengan jupyter dan notebook yang sudah teristall, prosesnya cukup run command berikut di direktori hasil clone repo udacity:
jupyter notebook
Ini adalah kode training pertama yang diambil dari notebook Part 3 - Training Neural Networks (Exercises).
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Assuming that we are on a CUDA machine, this should print a CUDA device:
print(device)
model = nn.Sequential(nn.Linear(784, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 10),
nn.LogSoftmax(dim=1)).to(device)
criterion = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=0.003)
epochs = 5
for e in range(epochs):
running_loss = 0
for images, labels in trainloader:
images, labels = images.to(device), labels.to(device)
# Flatten MNIST images into a 784 long vector
images = images.view(images.shape[0], -1)
# Clear the gradients, do this because gradients are accumulated
optimizer.zero_grad()
# Forward pass, then backward pass, then update weights
output = model(images)
loss = criterion(output, labels)
loss.backward()
# Take an update step and few the new weights
optimizer.step()
running_loss += loss.item()
else:
print(f"Training loss: {running_loss/len(trainloader)}")
Untuk device = 'cpu' penggunaan prosesornya hampir selalu penuh (100%) selama periode training.
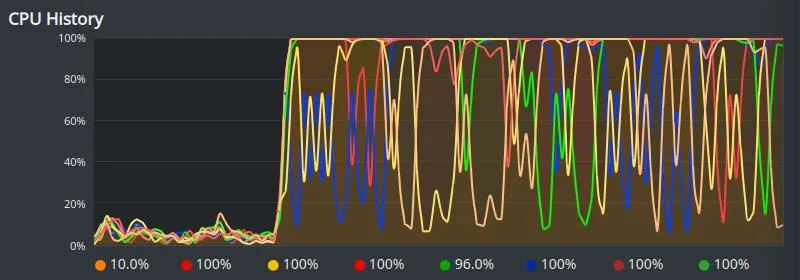
Saat dipindahkan ke GPU dengan device = 'cuda:0' penggunaan prosesornya hanya sesekali penuh saat periode training.
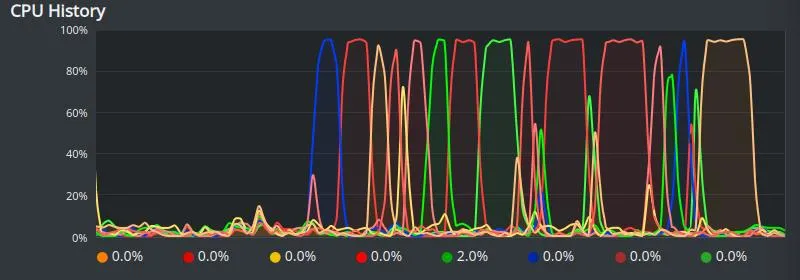
TBD